Why the Khasi Language Needs Its Own AI Model
The Challenge for Low-Resource Languages
Most large language models fail to handle Khasi properly because:
- Tokenization inefficiency: Khasi words are broken into many subwords, wasting context and reducing fluency.
- No high-quality corpus: Public datasets contain contamination, code-mixing, and noise.
- Bilingual instability: Generic models auto-translate English prompts, echo instructions, or mix languages unpredictably.
- Limited academic focus: Northeast Indian languages are rarely included in multilingual benchmarks or foundational model research.
These issues block Khasi speakers from benefiting fully from generative AI.
Introducing Kren-M
Meghalaya’s First Foundational AI Model
Kren-M solves these challenges using a fully customized approach:
- 2.6B-parameter bilingual model built on Google’s Gemma-2-2B architecture.
- 2,135 custom Khasi–Garo tokens added via SentencePiece vocabulary extension.
- 30–36% token efficiency improvement compared to Gemma-2-2B baseline.
- 5.43 million cleaned Khasi-language corpus for continued pre-training.
- 33,034 supervised instruction examples in Khasi chat, English chat, and translation.
- Response-aware SFT that eliminates auto-translation and echoing.
Technical Foundations
1. Custom Tokenizer for Khasi, Garo & the Northeast
We trained a specialized tokenizer to fix over-segmentation:
- 66,188 sentences (Khasi + Garo)
- 5,000-token SentencePiece model
- 2,135 new tokens added to Gemma’s base vocabulary
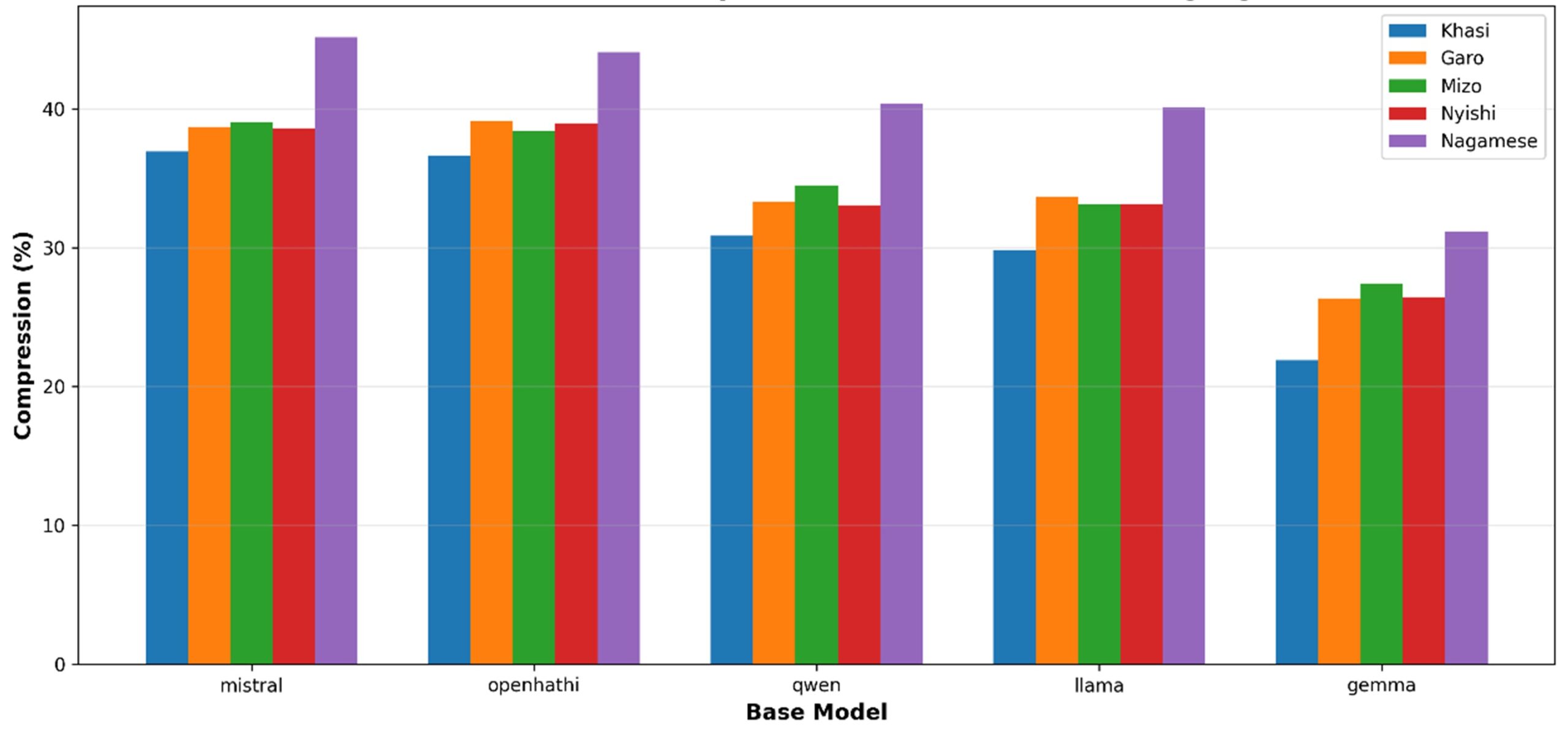
- 30–36% fewer tokens per Khasi/Garo sentence
- Accuracy improves because the model sees complete Khasi/Garo morphemes
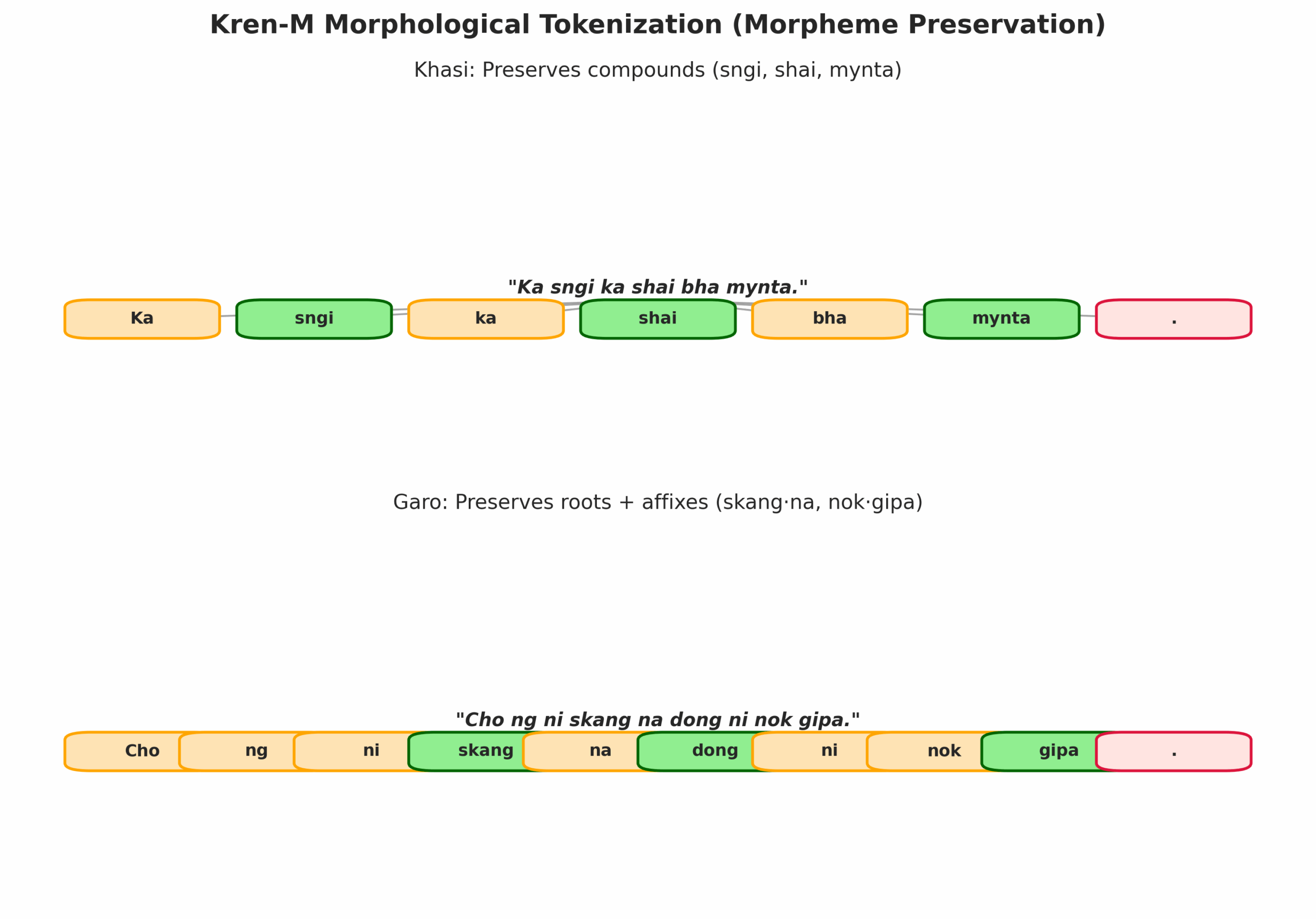
Kren-NE Tokenizer (New!)
MWire Labs now maintains Kren-NE, an expanding tokenizer project covering:
- Khasi
- Garo
- Mizo
- Assamese
- Manipuri (Meitei)
- Nagamese
- Nyishi
This positions Kren-NE as the first multi-language tokenizer for Northeast India, enabling future models beyond Kren-M.
2. Continued Pre-Training (CPT) — Clean Data First
We curated the largest Khasi text corpus to date:
- 5,433,041 sentences
- Removed HTML noise, verse citations, ellipses, auto-generated spam, mixed-script anomalies
- Two-stage CPT:
- Stage 1 (LR 2e-4): Validation loss → 2.974 (from 6.77 baseline)
- Stage 2 (LR 1e-4): Minor refinement
Result:
45.5% improvement in validation loss
Fluent Khasi generation with minimal artifacts.
3. Supervised Fine-Tuning (SFT)
We built a highly selective bilingual dataset:
- 10,097 Khasi translation pairs
- 15,000 English Dolly-style instruction pairs
- 7,937 Khasi conversational pairs
Critical fixes:
- Removed 9,903 implicit translations
- Implemented response-only loss masking
- Enforced EOS token at every sample
- Trained embed_tokens + lm_head for new vocabulary activation
Final SFT model loss: 0.85