Northeast India Language Identification Model
NE-LID is a high-accuracy language identification model and benchmark developed by MWire Labs for low-resource languages of Northeast India.
It addresses a critical gap in multilingual NLP by demonstrating that generic language identification systems fail on Northeast Indian languages, while character-level modeling remains highly effective.
Overview
NE-LID performs sentence-level language identification across 11 languages spoken in Northeast India and surrounding regions.
The model is built using a character n-gram fastText classifier, designed for short text, spelling variation, and script diversity.
Beyond releasing a production-ready model, NE-LID establishes a systematic benchmark comparing widely used language identification systems on Northeast Indian data.
Supported Languages
Assamese, Bodo, English, Garo, Hindi, Khasi, Kokborok, Meitei, Mizo, Nagamese, Nyishi
Scripts covered include Latin, Devanagari, Bengali-Assamese.
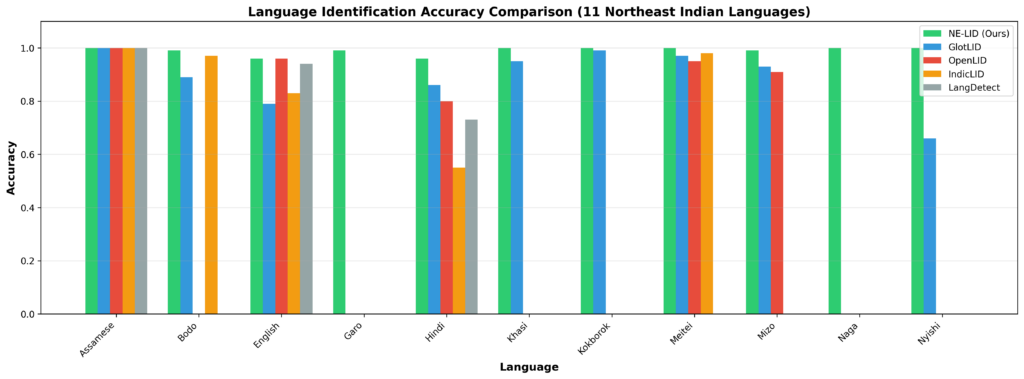
Benchmark Results.
NE-LID significantly outperforms existing language identification systems on Northeast Indian languages.
| Model | Accuracy |
|---|---|
| NE-LID (MWire Labs) | 99.09% |
| GlotLID | 73.12% |
| OpenLID | 42.03% |
| IndicLID | 39.30% |
| LangDetect | 24.33% |
These results show that even Indic-focused and multilingual LID systems struggle with script-diverse, low-resource Northeast Indian text.
Key Characteristics
- Accuracy: 99.09 percent on held-out test data
- Model type: fastText supervised classifier
- Features: Character n-grams (2–5)
- Inference speed: Sub-5 milliseconds per sentence
- Robustness: Stable across scripts and spelling variation
- License: CC BY 4.0
Why NE-LID
Transformer-based language models and generic LID tools often collapse to dominant languages when applied to Northeast Indian text.
NE-LID demonstrates, through extensive benchmarking, that simple character-level approaches outperform large neural models in this setting.
This makes NE-LID suitable for:
- Language routing for machine translation systems
- Preprocessing and filtering multilingual corpora
- Speech recognition language selection
- Government and institutional text pipelines
- Low-resource NLP research
Quick start
import fasttext
# Load the model
model = fasttext.load_model("ne_lid.bin")
# Predict language
text = "Ki paidbah shnong ki la ia shim bynta ha ka jingïalang"
labels, probs = model.predict(text)
print(f"Language: {labels[0].replace('__label__', '')}")
print(f"Confidence: {probs[0]:.4f}")
Let's Build Together
Are you a researcher, developer, or part of a language community in Northeast India? We are always looking for partners to collaborate on new datasets, fine-tune models, and advance the state of regional AI.