NE-BERT: Northeast India's First Multilingual Model
Standard global models treat our languages as “noise.” NE-BERT treats them as native. We built Northeast India’s first multilingual model on 8.3 million sentences to preserve, protect, and process our region’s diverse linguistic heritage.
Why the World Needs a Northeast Indian Multilingual Model.
Language technologies have historically ignored the complex linguistic landscape of Northeast India. Generic models like mBERT and IndicBERT struggle here because they are dominated by Hindi and Western languages.
NE-BERT is different. It is a domain-specific multilingual model built from the ground up for the region. By balancing Austroasiatic (Khasi, Pnar), Tibeto-Burman (Meitei, Garo, Mizo), and Indo-Aryan (Assamese, Nagamese) languages, we have created a single model that understands the unique context of the Northeast.
Nine Northeast Languages. One Model.
NE-BERT is the most comprehensive Northeast India multilingual model available today. We cover the “Big 9” distinct languages of the region
| Language | ISO Code | Script | Training Data (Sentences) |
| Assamese | asm | Bengali-Assamese | ~1,000,000 |
| Meitei (Manipuri) | mni | Bengali-Assamese | ~1,300,000 |
| Khasi | kha | Latin | ~1,000,000 |
| Mizo | lus | Latin | ~1,000,000 |
| Garo | grt | Latin | ~10,000 (Upsampled) |
| Nyishi | njz | Latin | ~55,000 (Upsampled) |
| Nagamese (Creole) | nag | Latin | ~13,000 (Upsampled) |
| Kokborok | trp | Latin | ~2,500 (Upsampled) |
| Pnar | pbv | Latin | ~1,000 (Upsampled) |
Note: Hindi and English are included as “Anchor Languages” to align the latent space.
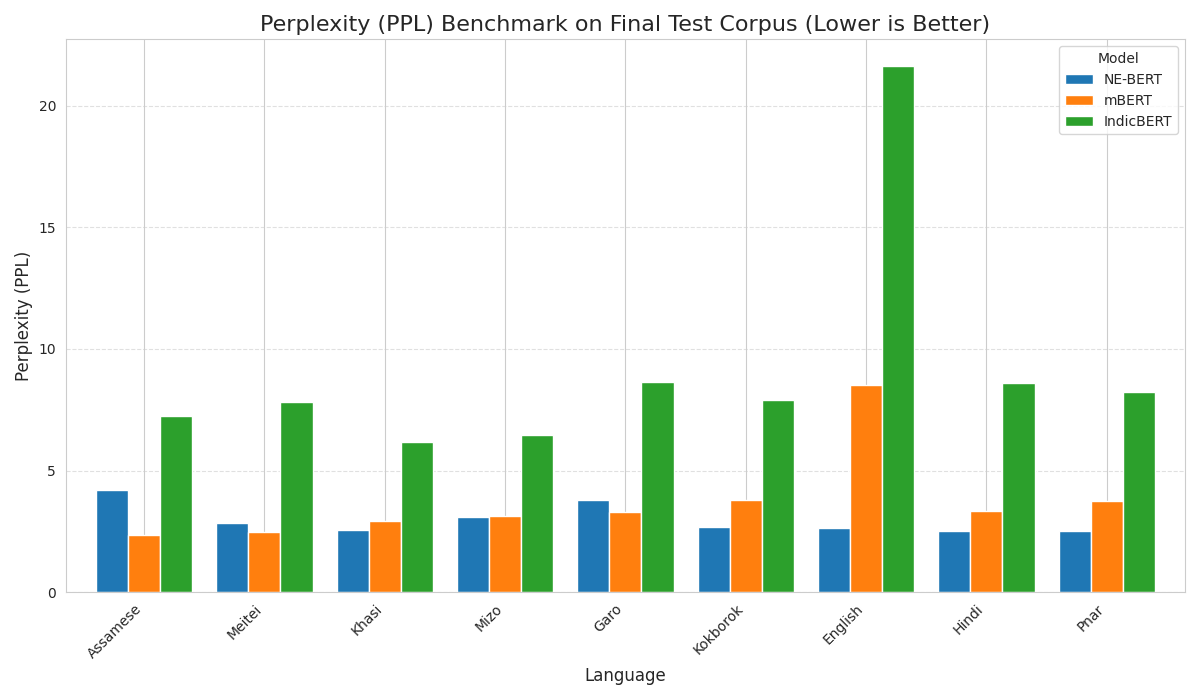
Efficiency: The Tokenization Advantage
Why is NE-BERT faster than Google’s mBERT? Tokenization.
Northeast Indian languages are highly agglutinative (complex words formed by sticking parts together). Standard models break our words into meaningless junk fragments. NE-BERT uses a custom SentencePiece Unigram Tokenizer optimized for our languages.
The “Fertility” Score (Lower is Better) Fertility measures how many tokens it takes to represent one word. Fewer tokens = Faster Speed + Longer Context.
| Model | Tokens per Word (Avg) | Efficiency Verdict |
| mBERT (Google) | 2.8 – 3.5 tokens | Slow & Fragmented |
| IndicBERT | 2.1 – 2.8 tokens | Average |
| NE-BERT (Ours) | 1.4 – 1.8 tokens | 1.6x Faster Inference |
This launch establishes Meghalaya as a new AI hub in Northeast India, setting the foundation for a broader regional language AI ecosystem.
What this means for you:
- Costs Less: You can process 2x more text for the same compute cost.
- Smarter: The model sees whole words (like “Khublei”) instead of fragments (“Khu”, “##ble”, “##i”), leading to better semantic understanding
Training Transparency
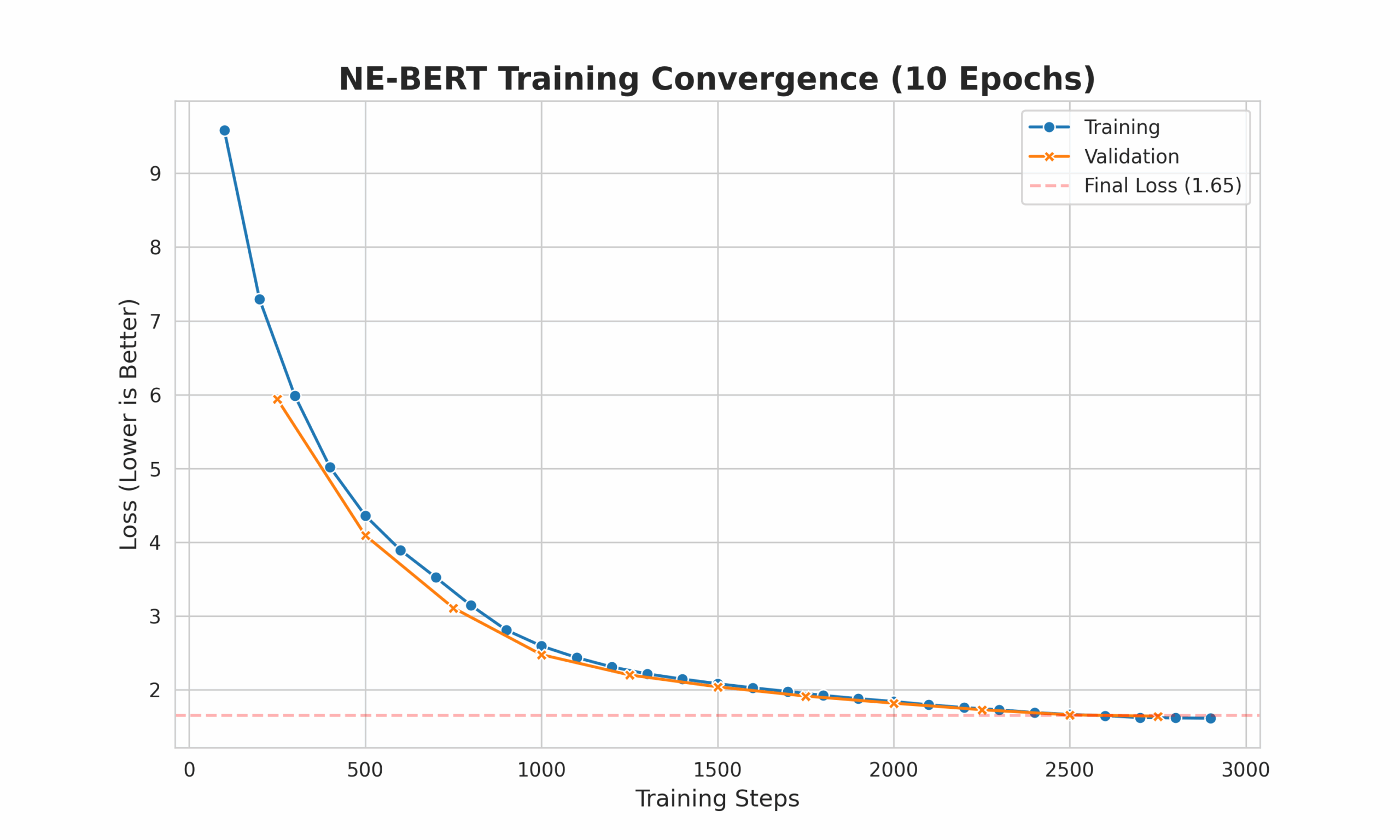
Full convergence achieved over 10 epochs with stable validation loss.
Quick start
from transformers import AutoTokenizer, AutoModelForMaskedLM
# Load NE-BERT
tokenizer = AutoTokenizer.from_pretrained("MWirelabs/ne-bert")
model = AutoModelForMaskedLM.from_pretrained("MWirelabs/ne-bert")
# Example: Nagamese Creole
text = "Moi bhat <mask>."
inputs = tokenizer(text, return_tensors="pt")
# Output: "khai" (eat)
Let's Build Together
Are you a researcher, developer, or part of a language community in Northeast India? We are always looking for partners to collaborate on new datasets, fine-tune models, and advance the state of regional AI.